
AI Research Scientist @ Meta
Yuren Cong (丛裕人)
Hello! I am a senior research scientist at Meta, building multi-modal understanding and generation models.
Previously I was a senior ML scientist at Picsart. I received my Ph.D. in Computer Science from Leibniz Hanover University, advised by Prof. Michael Yang and Prof. Bodo Rosenhahn.
News
- We release TUNA-2, a pixel-space unified model.
- TUNA accepted to CVPR26 Highlight.
- 3 papers accepted to CVPR 2026.
- We release TUNA, A multimodal understanding and generation model!
- Our GenAI solution for Ads is highlighted at Cannes Lions 2025.
Selected Publications
-

-

-
 Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation -

-

-
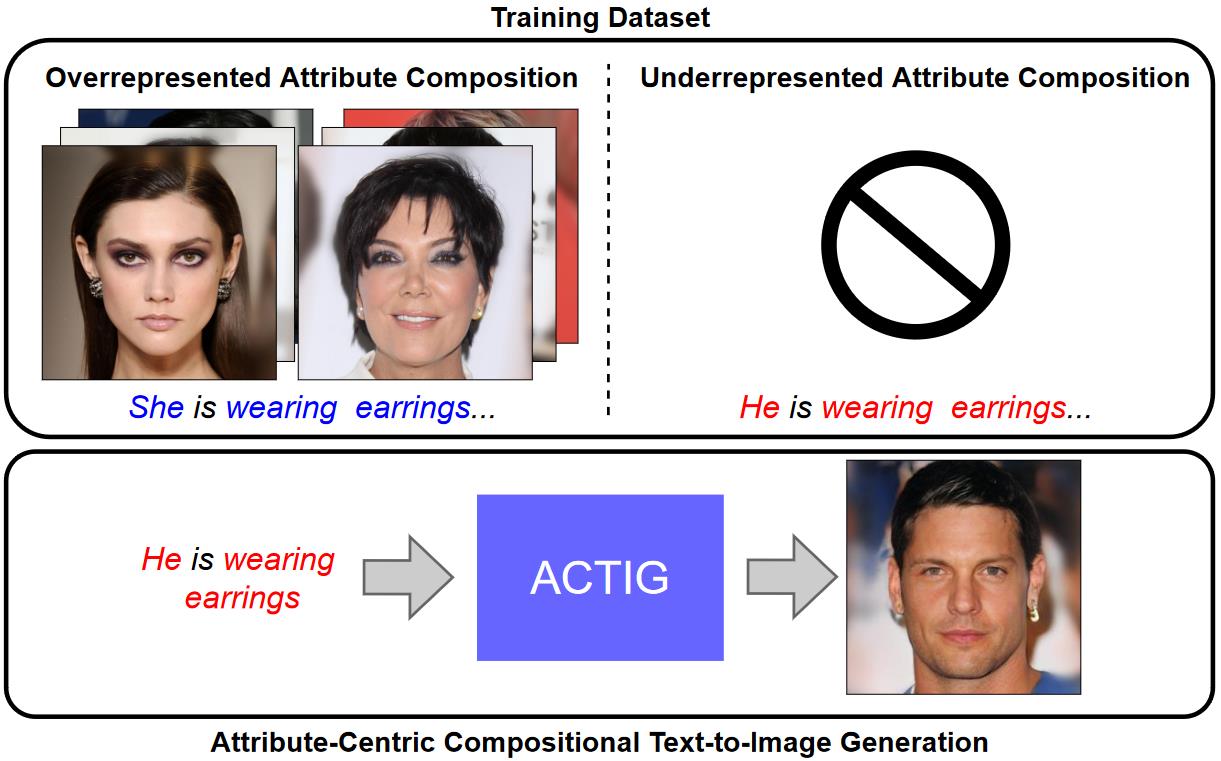 Attribute-Centric Compositional Text-to-Image Generation
Attribute-Centric Compositional Text-to-Image Generation -
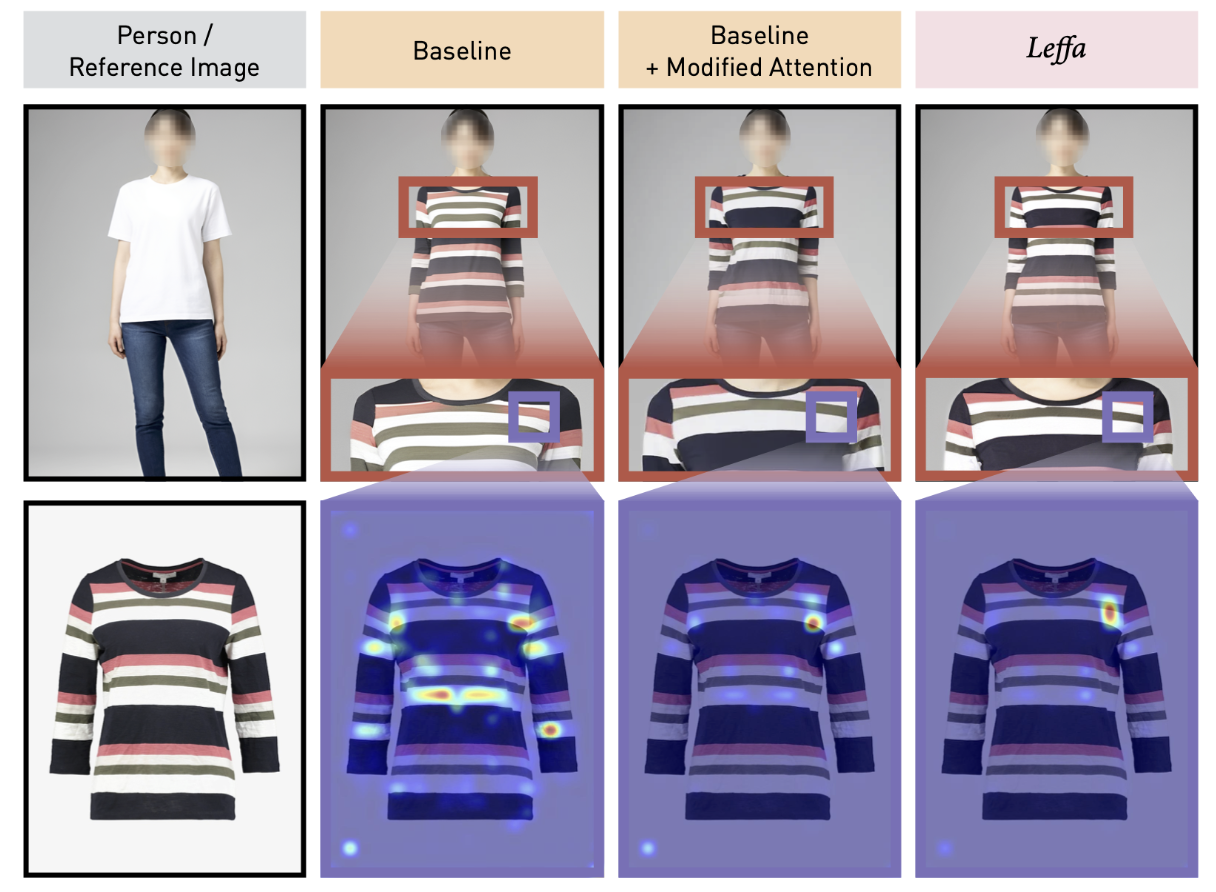 Learning Flow Fields in Attention for Controllable Person Image Generation
Learning Flow Fields in Attention for Controllable Person Image Generation -

-

-
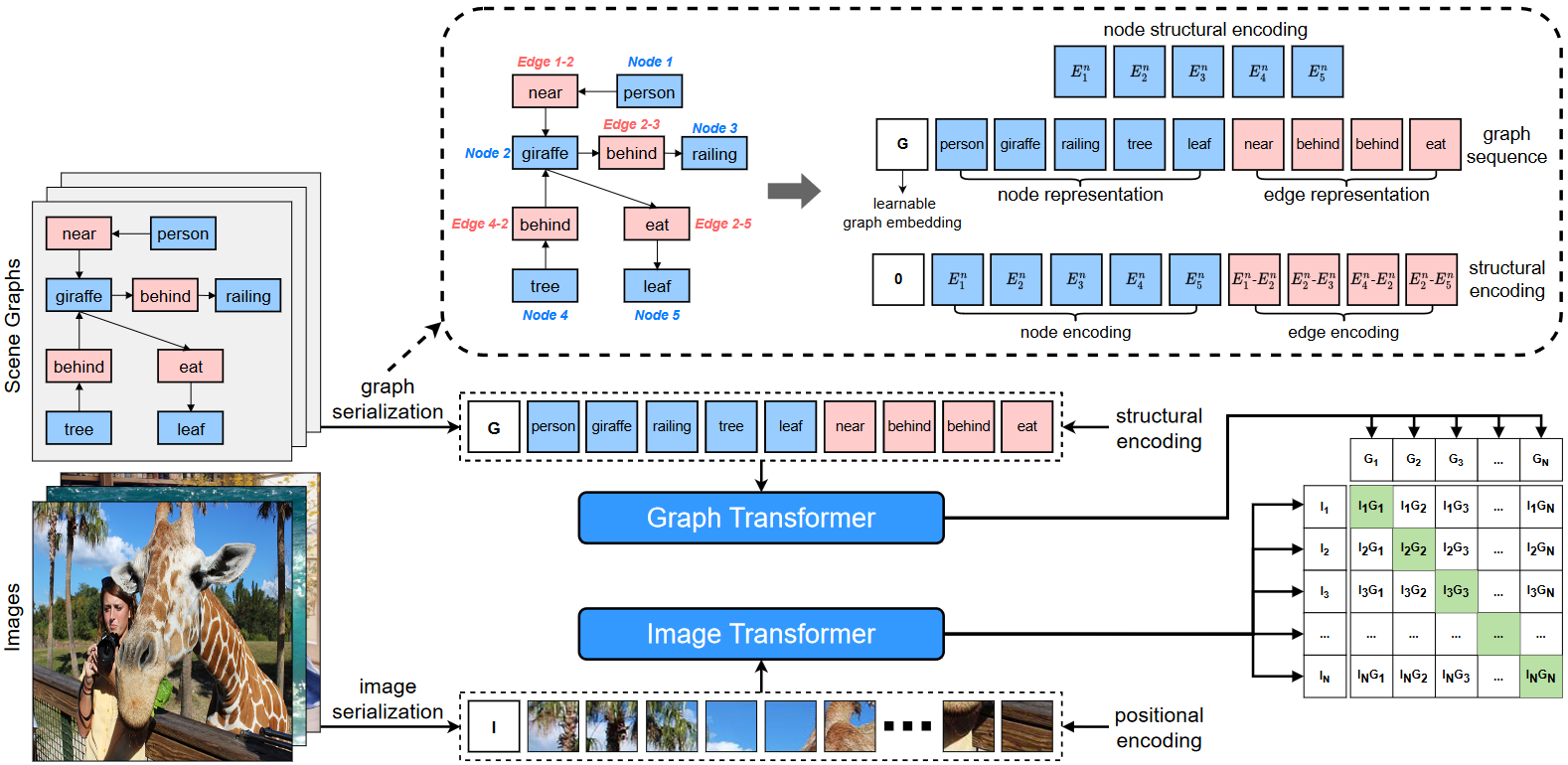 SPAN: Learning Similarity between Scene Graphs and Images with Transformers
SPAN: Learning Similarity between Scene Graphs and Images with Transformers -
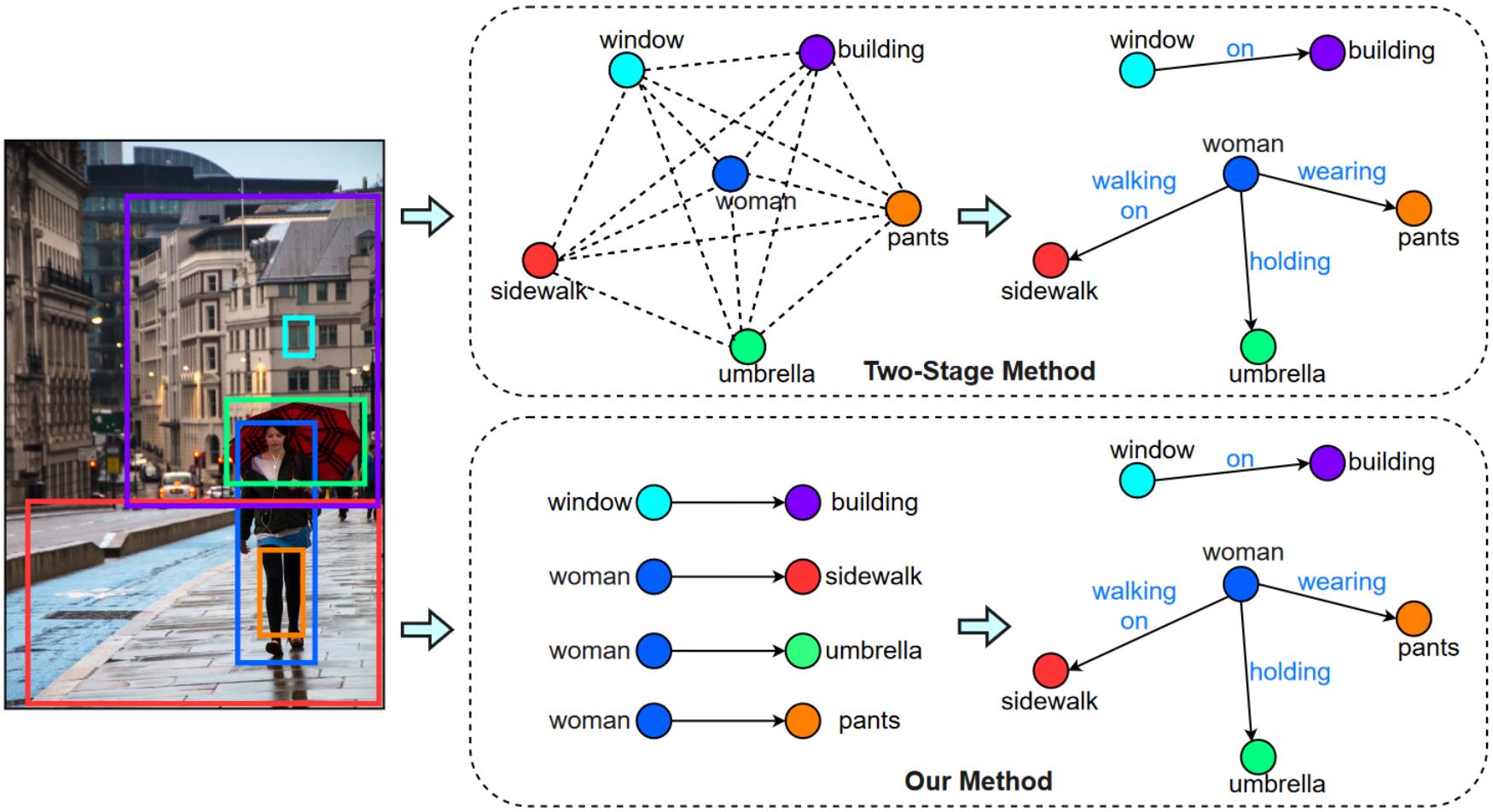
-
-
-
 Indoor Scene Change Understanding (SCU): Segment, Describe, and Revert Any Change
Indoor Scene Change Understanding (SCU): Segment, Describe, and Revert Any Change -
 Worldafford: Affordance Grounding Based on Natural Language Instructions
Worldafford: Affordance Grounding Based on Natural Language Instructions